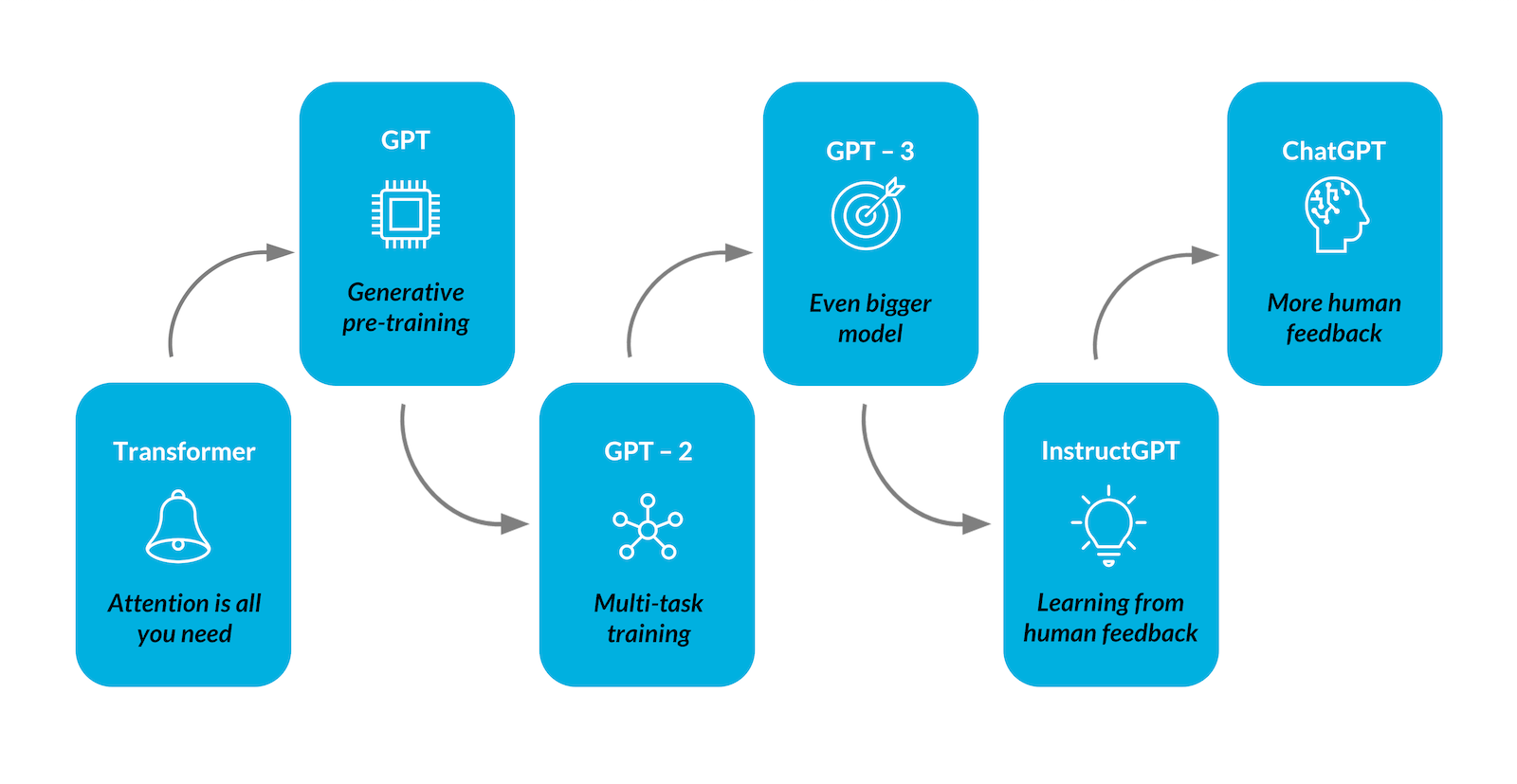
What is ChatGPT?
페이지 정보
작성자 Adelaide 작성일25-01-07 19:21 조회3회 댓글0건관련링크
본문
 News Gathering and Summarization: Grok 2 can reference specific tweets when gathering and summarizing news, a singular capability not found in ChatGPT or Claude. So, these big language fashions (LLMs) like ChatGPT, Claude and so forth. are wonderful - they will study new stuff with just some examples, like some sort of tremendous-learner. An excellent place to get started could be "A Mathematical Theory of Communication," a seminal paper revealed in 1948 by the mathematician Claude Shannon. This might lead to solutions which are inadvertently biased or discriminatory. There may be the risk that a finance crew member may disclose a commerce secret or proprietary information. How google suits Generative AI in there search outcomes. While there are various advantages to this transparency, there are additionally difficulties within the examine and understanding of the info. Unlike traditional language fashions, which use predefined rules to generate textual content, ChatGPT Nederlands uses a neural network to "learn" from present textual content data and generate text on its own.
News Gathering and Summarization: Grok 2 can reference specific tweets when gathering and summarizing news, a singular capability not found in ChatGPT or Claude. So, these big language fashions (LLMs) like ChatGPT, Claude and so forth. are wonderful - they will study new stuff with just some examples, like some sort of tremendous-learner. An excellent place to get started could be "A Mathematical Theory of Communication," a seminal paper revealed in 1948 by the mathematician Claude Shannon. This might lead to solutions which are inadvertently biased or discriminatory. There may be the risk that a finance crew member may disclose a commerce secret or proprietary information. How google suits Generative AI in there search outcomes. While there are various advantages to this transparency, there are additionally difficulties within the examine and understanding of the info. Unlike traditional language fashions, which use predefined rules to generate textual content, ChatGPT Nederlands uses a neural network to "learn" from present textual content data and generate text on its own.
 The mannequin makes use of a transformer architecture, which allows it to know the context of the text and generate text that is coherent and fluent. If you're pondering, why use ChatGPT, which allows you to touch actuality to a certain level solely? OpenAI's ChatGPT is currently freely accessibly in a public beta, so I wished to make use of the opportunity to judge whether I need to begin searching for a brand new job anytime soon. You will have now built your transcription app from begin to complete. Once deployed, it ought to redirect you to a success web page with a preview of the app. Think about that includes an interactive chatbot in your website or touchdown web page. Generating information variations: Think of the instructor as a data augmenter, creating totally different variations of existing knowledge to make the student a more properly-rounded learner. Several strategies can obtain this: - Supervised advantageous-tuning: The student learns straight from the teacher's labeled data.
The mannequin makes use of a transformer architecture, which allows it to know the context of the text and generate text that is coherent and fluent. If you're pondering, why use ChatGPT, which allows you to touch actuality to a certain level solely? OpenAI's ChatGPT is currently freely accessibly in a public beta, so I wished to make use of the opportunity to judge whether I need to begin searching for a brand new job anytime soon. You will have now built your transcription app from begin to complete. Once deployed, it ought to redirect you to a success web page with a preview of the app. Think about that includes an interactive chatbot in your website or touchdown web page. Generating information variations: Think of the instructor as a data augmenter, creating totally different variations of existing knowledge to make the student a more properly-rounded learner. Several strategies can obtain this: - Supervised advantageous-tuning: The student learns straight from the teacher's labeled data.
This will involve a number of approaches: - Labeling unlabeled data: The instructor model acts like an auto-labeler, creating training information for the pupil. This includes leveraging a large, pre-trained LLM (the "instructor") to practice a smaller "scholar" mannequin. Mimicking internal representations: The pupil tries to replicate the instructor's "thought process," learning to predict and cause similarly by mimicking inside chance distributions. The Student: This is a smaller, extra efficient mannequin designed to mimic the trainer's efficiency on a specific process. Reinforcement learning: The scholar learns through a reward system, getting "factors" for producing outputs nearer to the teacher's. The objective is to imbue the pupil mannequin with comparable efficiency to the trainer on a defined job, but with significantly reduced dimension and computational overhead. However, deploying this powerful model might be expensive and slow as a result of its dimension and computational demands. However, it does have another operate that's free to use. However, it will be significant to note that while ChatGPT in het Nederlands could be impressively relevant at occasions when provided precise prompts or questions with applicable context; it may also sometimes produce odd or incorrect answers.
These are a few of the extremely intriguing questions we'll discuss in this article. Increased Speed and Efficiency: Smaller fashions are inherently quicker and more environment friendly, resulting in snappier performance and diminished latency in purposes like chatbots. Reduced Cost: Smaller models are significantly more economical to deploy and operate. LLM distillation is a knowledge transfer approach in machine studying aimed toward creating smaller, more environment friendly language models. Running a 400 billion parameter mannequin can reportedly require $300,000 in GPUs - smaller fashions provide substantial savings. The Teacher: This is often a large, powerful model like Chat Gpt nederlands-4, Llama 3.1 45b, or PaLM that has been trained on an enormous dataset. It's like attempting to get the scholar to suppose just like the teacher. 2. Knowledge Distillation: The extracted information is then used to train the scholar. The Teacher-Student Model Paradigm is a key concept in model distillation, a method utilized in machine studying to transfer knowledge from a bigger, more complicated model (the instructor) to a smaller, easier mannequin (the pupil). While it could possibly produce fairly correct translations for easier texts, it could struggle with advanced sentence constructions or idiomatic expressions that require cultural context. 5. Text era: Once the enter message is processed and the dialog context is considered, ChatGPT generates a response utilizing its pre-educated language mannequin.
Warning: Use of undefined constant php - assumed 'php' (this will throw an Error in a future version of PHP) in /data/www/kacu.hbni.co.kr/dev/skin/board/basic/view.skin.php on line 152
댓글목록
등록된 댓글이 없습니다.
