Choosing Deepseek
페이지 정보
작성자 Carol 작성일25-02-03 21:26 조회4회 댓글0건관련링크
본문
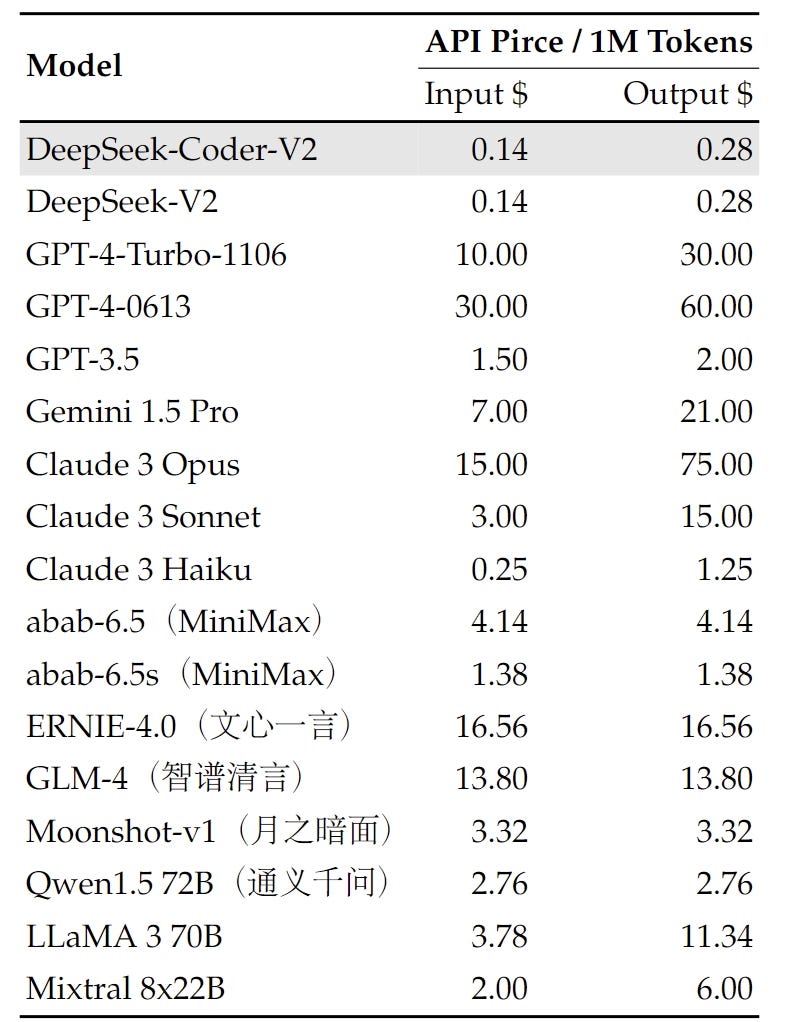 • We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 collection models, into commonplace LLMs, significantly DeepSeek-V3. My level is that maybe the method to make cash out of this is not LLMs, or not only LLMs, but different creatures created by wonderful tuning by massive companies (or not so large firms essentially). The fundamental architecture of DeepSeek-V3 is still within the Transformer (Vaswani et al., 2017) framework. For engineering-associated duties, whereas DeepSeek-V3 performs slightly below Claude-Sonnet-3.5, it still outpaces all different fashions by a major margin, demonstrating its competitiveness throughout diverse technical benchmarks. We’ll get into the precise numbers under, however the question is, which of the various technical innovations listed within the DeepSeek V3 report contributed most to its learning effectivity - i.e. model efficiency relative to compute used. In the first stage, the utmost context length is prolonged to 32K, and within the second stage, it's further extended to 128K. Following this, we conduct put up-coaching, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the bottom mannequin of DeepSeek-V3, to align it with human preferences and additional unlock its potential. The fashions are roughly based mostly on Facebook’s LLaMa family of models, though they’ve changed the cosine learning rate scheduler with a multi-step studying rate scheduler.
• We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 collection models, into commonplace LLMs, significantly DeepSeek-V3. My level is that maybe the method to make cash out of this is not LLMs, or not only LLMs, but different creatures created by wonderful tuning by massive companies (or not so large firms essentially). The fundamental architecture of DeepSeek-V3 is still within the Transformer (Vaswani et al., 2017) framework. For engineering-associated duties, whereas DeepSeek-V3 performs slightly below Claude-Sonnet-3.5, it still outpaces all different fashions by a major margin, demonstrating its competitiveness throughout diverse technical benchmarks. We’ll get into the precise numbers under, however the question is, which of the various technical innovations listed within the DeepSeek V3 report contributed most to its learning effectivity - i.e. model efficiency relative to compute used. In the first stage, the utmost context length is prolonged to 32K, and within the second stage, it's further extended to 128K. Following this, we conduct put up-coaching, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the bottom mannequin of DeepSeek-V3, to align it with human preferences and additional unlock its potential. The fashions are roughly based mostly on Facebook’s LLaMa family of models, though they’ve changed the cosine learning rate scheduler with a multi-step studying rate scheduler.
![]() "This run presents a loss curve and convergence price that meets or exceeds centralized coaching," Nous writes. While the paper presents promising outcomes, it is crucial to contemplate the potential limitations and areas for further analysis, akin to generalizability, moral concerns, computational efficiency, and transparency. While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual information (SimpleQA), it surpasses these fashions in Chinese factual data (Chinese SimpleQA), highlighting its strength in Chinese factual knowledge. Understanding the reasoning behind the system's choices may very well be valuable for building trust and further enhancing the strategy. Notably, it even outperforms o1-preview on particular benchmarks, akin to MATH-500, demonstrating its robust mathematical reasoning capabilities. 2) For factuality benchmarks, DeepSeek-V3 demonstrates superior efficiency amongst open-supply fashions on both SimpleQA and Chinese SimpleQA. 2) On coding-associated tasks, DeepSeek-V3 emerges as the highest-performing model for coding competition benchmarks, equivalent to LiveCodeBench, solidifying its position because the main model in this domain. As businesses and developers seek to leverage AI more efficiently, DeepSeek-AI’s newest release positions itself as a top contender in both basic-objective language tasks and specialized coding functionalities.
"This run presents a loss curve and convergence price that meets or exceeds centralized coaching," Nous writes. While the paper presents promising outcomes, it is crucial to contemplate the potential limitations and areas for further analysis, akin to generalizability, moral concerns, computational efficiency, and transparency. While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual information (SimpleQA), it surpasses these fashions in Chinese factual data (Chinese SimpleQA), highlighting its strength in Chinese factual knowledge. Understanding the reasoning behind the system's choices may very well be valuable for building trust and further enhancing the strategy. Notably, it even outperforms o1-preview on particular benchmarks, akin to MATH-500, demonstrating its robust mathematical reasoning capabilities. 2) For factuality benchmarks, DeepSeek-V3 demonstrates superior efficiency amongst open-supply fashions on both SimpleQA and Chinese SimpleQA. 2) On coding-associated tasks, DeepSeek-V3 emerges as the highest-performing model for coding competition benchmarks, equivalent to LiveCodeBench, solidifying its position because the main model in this domain. As businesses and developers seek to leverage AI more efficiently, DeepSeek-AI’s newest release positions itself as a top contender in both basic-objective language tasks and specialized coding functionalities.
OpenAI ought to release GPT-5, I believe Sam stated, "soon," which I don’t know what that means in his thoughts. DeepSeek (Chinese AI co) making it look easy at present with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for two months, $6M). Within the latest months, there has been a huge pleasure and interest around Generative AI, there are tons of bulletins/new innovations! Jordan Schneider: Alessio, I need to return again to one of many belongings you said about this breakdown between having these research researchers and the engineers who are more on the system aspect doing the precise implementation. Throughout the complete coaching process, we did not encounter any irrecoverable loss spikes or have to roll back. • We design an FP8 combined precision training framework and, for the primary time, validate the feasibility and effectiveness of FP8 training on an especially massive-scale mannequin. For the DeepSeek-V2 mannequin collection, we choose essentially the most consultant variants for comparability. For environment friendly inference and economical coaching, DeepSeek-V3 also adopts MLA and DeepSeekMoE, which have been completely validated by DeepSeek-V2. We first introduce the essential structure of DeepSeek-V3, featured by Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for efficient inference and DeepSeekMoE (Dai et al., 2024) for economical training.
Lastly, we emphasize again the economical training costs of DeepSeek-V3, summarized in Table 1, achieved by our optimized co-design of algorithms, frameworks, and hardware. Figure 2 illustrates the basic architecture of DeepSeek-V3, and we'll briefly overview the small print of MLA and DeepSeekMoE on this section. Basic Architecture of DeepSeekMoE. Compared with DeepSeek-V2, an exception is that we additionally introduce an auxiliary-loss-free load balancing technique (Wang et al., 2024a) for DeepSeekMoE to mitigate the efficiency degradation induced by the trouble to make sure load stability. For Feed-Forward Networks (FFNs), DeepSeek-V3 employs the DeepSeekMoE structure (Dai et al., 2024). Compared with conventional MoE architectures like GShard (Lepikhin et al., 2021), DeepSeekMoE uses finer-grained experts and isolates some experts as shared ones. DeepSeek-V3 series (including Base and Chat) helps industrial use. • At an economical price of solely 2.664M H800 GPU hours, we complete the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the currently strongest open-source base mannequin. During the pre-training stage, coaching DeepSeek-V3 on each trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. But these instruments can create falsehoods and often repeat the biases contained within their coaching knowledge.
Warning: Use of undefined constant php - assumed 'php' (this will throw an Error in a future version of PHP) in /data/www/kacu.hbni.co.kr/dev/skin/board/basic/view.skin.php on line 152
댓글목록
등록된 댓글이 없습니다.
